
Security Tip: Avoiding Filename Collisions
[Tip#55] Let's look at my old buddy time(), who always has something for me during my audits. This time it's helping avoid filename collisions?

A very common pattern I’ve come across during my audits is around generating filenames and the desire to avoid collisions.
I’ll often find code that looks like this:
function generateFilename($originalName, $extension): string
{
$hash = substr(md5($originalName), 0, 5);
return time().random_int(100, 1000).$hash.'.'.$extension;
}When writing the code, the developer is clearly thinking about (in this order):
- Avoiding naming collisions
- Making the name unique
- Limiting the length and/or characters used
- Security?
They’ve immediately reached for time() (or if they’re lucky microtime()) to provide unique names, added in some small randomness and hashed the original name for more uniqueness, and a known length, and called it a day.
We may laugh or groan about it now, but if we’re honest with ourselves as developers, we know we’ve done this exact thing before. The concern was about collisions and uniqueness, and the fact that using randomness opens up a possibility for a collision (however small), so the developer brain sought out a different solution…
Ignoring the fact that this doesn’t actually avoid collisions, the format is incredibly predictable. If you were attacking this app, trying to identify the filename format, the timestamp would jump out immediately, and you’d already have various MD5 hashes already generated and be looking for them. All you’d need is the random number in the middle, of which there are 900 possible values (assuming my maths is correct?). That won’t take long to find when you’re looking for a specific file around a specific time.
So what’s the solution to this?
This may be controversial, but I recommend you just use more randomness. You could back it up with a unique column in a DB (which you may need anyway), but I’d just generate a sufficiently long random string and use that for your filenames.
The more random a string you generate, the lower the chances of collisions actually are, so I suggest just swapping all of the logic out for a lengthy random string.
For example, instead of:
// time().random(100, 1000).$hash.'.'.$extension
1660338149543ab3d.pngJust use this:
// Str::random(16)
CHQvtbkA89jC1Ojl.pngUpdate
After posting this article, Tim Düsterhus over on the Fediverse made the excellent point about my length of 16 in the above example:
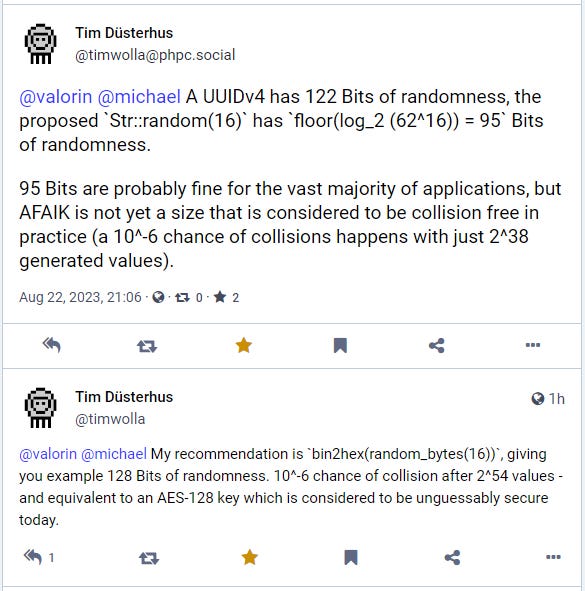
Tim pointed out that Str::random(16) only generates 95 bits of randomness, while 128 bits of randomness is currently considered unguessable by today’s computing standards. By his estimate, this can be achieved by using Str::random(22), or using his recommended approach: bin2hex(random_bytes(16)).
He then went on to talk about timing attacks and implementations, which I recommend you check out if you’re interested in diving deeper. Timing attacks won’t be an issue for the filename collisions we talked about above, but they could be an issue for other uses of Str::random() in specific implementations.
If you found this security tip useful, subscribe to get weekly Security Tips straight to your inbox. Upgrade to a premium subscription for exclusive monthly In Depth articles, or drop a coin in the tip jar to show your support.
When was the last time you had a penetration test? Book a Laravel Security Audit and Penetration Test, or a budget-friendly Security Review!
You can also connect with me on Bluesky, or other socials, and check out Practical Laravel Security, my interactive course designed to boost your Laravel security skills.



